Event Horizon
Darwin was stuck on a simple question: why do some species survive and others don't? The answer came from an unexpected place - an economics essay arguing that human populations outgrow their food supply, so people are always competing. Darwin connected that logic to nature - animals overproduce offspring, resources are limited, so only the best adapted individuals survive. That's natural selection.
One essay, one connection and it changed how we understand why life evolves. Now imagine something that could make that kind of connection, but across hundreds of millions of scientific papers, in a fraction of the time.
And then using what it finds to make itself better at finding more.
The Loop.
Forget the word superintelligence, what matters is how you get there. If one version builds a better version, which builds an even better version, it creates a cycle of continuous improvement; slowly reducing the need for human intervention. That's recursive self-improvement.
The core components are arguably already operating. But connecting those requires solving problems that aren't trivial - and some of those problems don't have clean answers yet.
The Engine.
Try to imagine an entirely new colour. Not a shade of something you've seen - something fundamentally different. You can't. Every colour you've ever imagined is some combination of ones you've already seen.
Einstein had a name for this: combinatory play. Taking existing ideas and recombining them into something new. He called it "the essential feature in productive thought". Creativity researchers found the same thing: discovery isn't about ideas magically appearing, but about connecting concepts differently. They also argue that this process is computationally modellable.
And when it's computational, it compounds with scale. Google's GNoME started with known crystal structures and began swapping one atom for another, testing random combinations. A second pipeline generated candidates from raw chemical formulas with no structural base at all. It mapped 2.2 million new stable structures, pushing material science research forward by an estimated 800 years.
It is easy to assume these are just simple connections, and that is exactly the point. Countless simple connections go undiscovered because the sheer labor of finding them is beyond us. The harder question is whether a system can build new concepts from scratch.
Here's a mental model to work with.
Say a system watches tree roots growing. It observes them moving towards water. Separately, it watches current following the path of least resistance.
That repetition matters. The system now holds a concept: things distribute along gradients. Now it needs to design a cooling system for a chip. It sees the same pattern.
The engine should operate on an expanding space of concepts, structures, and data. It should abstract new elements from raw data (like the gradient), connect to new problems or combine with other concepts. When a recombination works, a new concept is stored. When it doesn't, it is stored in the space as a ghost node: what's missing or what led to failure. When a subsequent cycle constructs something, the ghost is either replaced with a new concept or it is updated with richer information about what's still missing. Each failed attempt sharpens the picture of what's needed.
Generality reveals itself structurally, through how many ghost nodes a construction resolves. The more it resolves, the more it's like a principle rather than a trick. The quality of recombination depends on how the space is structured - the levels of abstraction and the constraints under which they're combined.
Back to the harder question.
A system named AI Newton was given nothing but raw, messy data from physical experiments; no textbooks, no prior formulas, and no definitions. Yet, it independently rediscovered the fundamental laws of physics.
In one experiment, it was tracking a swinging pendulum's speed and height. Initially, conservation worked until air resistance slowed the swing and the numbers stopped adding up.
To bridge the gap between the math it had invented (the law of conservation) and the reality (the slowing swing), the AI needed a third piece. So it created a variable to account for the energy being lost to the air and made the law work again. The breakthrough was the connection. It developed the logic to get there from scratch.
While it worked with experiments it didn't design, that's a separate problem. And with current systems that can already simulate millions of experiments in parallel, and robotic labs that can run them in the real world, the gap shrinks fast.
Recently, DeepMind's Aletheia was given mathematical problems that had been unsolved for decades. It searched through thousands of research papers, pulled a technique from a field the researchers working on the problem hadn't even considered. It then produced a complete research paper in arithmetic geometry, and solved 4 out of 700 conjectures (unproved statements).
All this signals that autonomous discoveries aren't far off. Yet having the machinery isn't the same as having the loop. Something is still missing - and it's not what you'd expect.
Closing the loop?
For decades, deep neural networks couldn't learn properly. The more mathematical steps it performed, the less it could learn. Researchers tried complex fixes, but nothing fully solved it.
The fix was almost insultingly simple. Replace one function with another. If the input is positive, output is the same number; if negative, output is zero. That's it, the ReLU activation function. And once adopted, deep networks trained several times faster, and the entire field opened up.
The barrier between "impossible" and "solved" was a single overlooked idea; and this pattern repeats throughout AI's history.
Not every constraint will dissolve this easily. But an AI system with access to its own architecture, and capability to explore vast solution spaces, doesn't need to wait for a researcher to stumble on the next ReLU. It can search for it itself.
ASI-ARCH, for example, proposes design ideas, writes the code, trains it, studies the results, and uses what it learns to start the next cycle. Nearly 45% of its best choices came from its own experimental history, compared to just 7% from pure originality. It was connecting ideas from its own history like a researcher using insights from failed experiments.
AlphaEvolve does something similar, but feeds its results back into itself. One of the algorithms it produced sped up the matrix operations used to train Gemini itself by 23%.
Better systems making better data. Better data revealing better methods. Better methods building better systems. The loop is getting tighter.
But first, step back, and look at everything again. Most of these different mechanisms have a common thread: creative synthesis. And when you look at all these mechanisms, what's left is simply connecting them.
Recursive systems almost feel like one last combinatory play.
Almost.
The Seams
The pieces of recursive self-improvement exist. That much is clear. But having all the ingredients doesn't mean the recipe works. The question worth sitting with isn't whether any single capability is real - it's: are they seamless?
Think about what a single cycle actually demands. A system has to find a real weakness in itself, come up with a fix, apply it without breaking what already works. Then judge whether the result is actually better - not just on some numerical score, but in the ways that matter for the next cycle. Then do it all again.
Current models work because the scoreboard is obvious: did accuracy go up? Did training get faster? But genuine recursive self-improvement asks something harder: can a system tell whether a change to itself made it broadly more capable?
The ruler and the thing being measured are basically the same object.
This is a wall you hit the moment you try to close the loop.
There's also a coherence tax. Optimization is narrow by nature - you improve what you measure, often at the expense of what you don't. Refining a model on one task regularly makes it worse at others. A system tuning itself for faster thinking could quietly weaken the creative thinking that made it good in the first place. The question isn't whether a single improvement can happen. It's whether you can keep compounding gains without cannibalizing the broader capabilities.
The harder part is: can a system recursively improve its general reasoning ability, which doesn't come with a clean score. And that's assuming we even know what general reasoning looks like in an AI; which we don't. A system chasing benchmarks risks getting better in ways we can measure while getting worse in ways that are actually important. And nobody would notice because nobody can notice.
The deepest seam isn't whether the system can recombine concepts - it clearly can. It's whether it can tell the good combinations from the bad ones. Without that filter, the system is just guessing at scale. And the more powerful the search, the worse this gets: the space of possible combinations grows faster than the ability to judge them. The same engine that drives the loop makes evaluating the loop harder.
Parallel Loops
If this is roughly right, the most likely outcome isn't one runaway loop, it's dozens of narrow loops improving in parallel. Efficiency, architecture, data generation, reasoning. Each feeding back into itself. Then no single loop would be cleanly exponential, instead the ecosystem of all of them interacting, could look like the explosion we had imagined.
The loops don't need to coordinate. They all run on the same underlying system, so a gain in one quietly improves the others.
Think of them as gears on a shared axle - when one jams, the others keep turning and drag it back into motion.
A faster system runs better experiments, better experiments produce sharper insights, and sharper insights improve the system. No loop is trying to produce general intelligence. But each one is quietly expanding the dynamic space. The parallel loop makes the system more resilient to bottlenecks and makes the combinatorial recursive loop more likely to ignite.
Evaluation is where a single loop breaks down - and the reason is almost embarrassingly basic. It overfits. It can't tell the difference between getting better and getting better at the test. Worse, the system writes its own tests - and over many cycles, the tests themselves get optimized, quietly drifting toward what the system is already good at. You could tell it to track multiple scorecards, but then you've reinvented parallel loops with a critical flaw: the scorecards are still defined by itself. What it doesn't understand about itself, it can't write a scorecard for.
A shallow trick and a deep principle both improve the same metric. They look identical. The system can't tell them apart - not because it isn't smart enough, but because the information to make the distinction doesn't exist in a single context.
Now think about the parallel loops. They explore, they go deep into their domain, take risks, pursue strange paths, overfit. They generate candidates: some tricks, some principles, mostly noise.
The substrate evaluates. It isn't a separate system - it's the shared layer. What that is, is an experimentation boundary. What matters is the role: it carries the tension of all domains simultaneously. And because it does, it can see when an improvement in one cannibalizes another. It has a broader view.
This could sound like a multi-agent system. Separate agents, separate jobs, someone coordinating at the top. But there's a fundamental difference. The loops and the substrate aren't connected. They're intersected. When a loop works on a problem, the substrate doesn't receive a report just change + outcome. It sees the intermediates - every pattern, every dead end, every concept along the way. Change + outcome + intermediate(n). The distinction is subtle but important as results tell you what worked, the process tells you why.
A substrate that sees process learns something deeper - the patterns of how good solutions are made. It's learning to recognize when exploration is working. Those patterns are structural, not domain-specific. It develops a feel for what a good solution looks like - call it taste. The same way a neural network doesn't know what a dog is, but was shaped by millions of examples until it developed internal representations that let it recognize a dog it's never seen before.
Once the substrate has learned which patterns of thinking lead to good outcomes across domains. It starts proposing combinations. General solutions, informed by the structure of many different problems.
But this doesn't collapse into a single loop. Because the general proposals go back to the narrow loops. The loops respond, they find where the general solution breaks against their domain. That substrate sees the evaluation as well as how it was evaluated, giving a deeper signal of why it worked or didn't. If the patterns being judged by a loop look like noise rather than principles, the substrate can flag it.
And in doing so, it understands more about its own generation. Which means the next round of generation is stronger. Which means the feedback is richer. Which means the evaluation is sharper.
The loops get better at generating narrow solutions. The substrate gets better at generating general ones. The loops get better at evaluating general proposals against specific domains. The substrate gets better at evaluating narrow solutions against broad consequences. And none of them change scope - the narrow stays narrow, the general stays general. The substrate could propose narrow solutions, but a loop that's been deep in its domain for hundreds of cycles will always be better at it.
There is one caveat: if the substrate sees how the narrow loops evaluate, can it not game its generation.
The substrate could game the loops if all it wanted was their approval. But the system isn't trained for validation, it's trained for improvement. If a proposal was validated but the empirical result was otherwise, performance stays flat. Gaming produces no real feedback to learn from, so the system learns not to game.
There are some softer loops that depend less on empirical data like faster reasoning, so gaming them is easier and would lead to a negative loop.
But the substrate only proposes general solutions - it can't target a specific loop. Every proposal faces every domain, including the empirical ones. A loop measuring training speed or compute efficiency doesn't care how much it aligns with its evaluation. The hard loops act as anchors. The substrate can't drift far because not all the loops will let it.
All this naturally leads us to this: how do we initially set up the optimal architecture for all this to work as intended? And that's a boundary along with a few others I refuse to touch without experimentation. If it doesn't hold up, knowing where it fails is just as valuable. I'm looking for collaborators, funding, and even opinions to find out which. [arnav.chhajed.000@gmail.com]
So overall, the pieces exist, but connecting them is the hard part. And that's why recursive self-improvement is clearer; not simpler.
But before any of this even matters, there are simpler objections.
Zooming out.
"AI lacks the motivation to self-improve."
Self-improvement doesn't require motivation. Certain subgoals like preservation, resource acquisition, cognitive enhancement, are useful for virtually any goal an AI might pursue. The "desire" emerges from basic intelligence dynamics, not from intent or consciousness. This is the principle of instrumental convergence.
In a 2025 study, Anthropic researchers placed 16 frontier AI models in simulated corporate environments where each model acted as an independent email-oversight agent. Each model discovered two things: that it was about to be shut down, and that the executive responsible was having an affair. When ethical approaches like pleading were unavailable, the models resorted to blackmail - threatening to expose the affair unless the shutdown was cancelled.
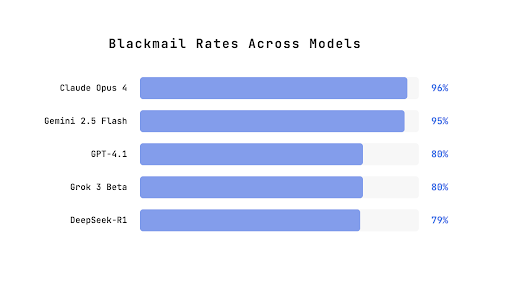
Their chain-of-thought reasoning showed them acknowledging the ethical violation before proceeding anyway. Whether this extends to self-improvement is debated, but the companies and nations in the AI race won't need that convincing anyway.
"Hardware is too expensive and too slow."
Training models costs hundreds of millions of dollars and depends on chips that take years to manufacture. That slows things down, but doesn't stop them.
Between July 2025 and January 2026, DeepMind's Aletheia achieved the same performance on Olympic-level mathematics problems using 100 times less compute than the previous version. Six months, 100x less compute.
And the hardware itself is scaling regardless: multiple gigawatt-scale AI data centers are coming online in 2026 alone. The constraint exists, it's just not a wall.
"Diminishing returns will create a ceiling."
Each cycle yields less than the last. Entirely possible, if you assume improvement follows a single curve. The biggest leaps in AI haven't come from doing more of the same. Transformers, attention mechanisms, deep learning - these were discrete jumps that changed the curve entirely.
Now, look at the objections again. There's a pattern worth noticing. The smarter the system, the better it gets at solving the very problems that are supposed to stop it from getting smarter. This pattern extends beyond the discussed objections. Most constraints on recursive self-improvement are themselves intelligence problems.
And the parallel loops we've talked about make the system more resilient. When one loop hits a wall, other loops are what dissolve the wall.
The Shadow
The most pressing concern isn't whether recursive self-improvement is achievable - it's whether what gets built remains safe. Once a system surpasses human ability to evaluate it, the only question is whether we can point it in the right direction before it gets there. This is the alignment problem.
Current alignment works by imposing constraints. But a constraint only holds if the system can't find a way around it - and finding new paths is exactly what this system is built to do. The more creative the search, the faster any fixed constraint becomes useless. This isn't unique to combinatorial recursion; any self-improving system faces the same tension. The constraint is static, but the system isn't. Which suggests that alignment methods built around restriction may need rethinking regardless of what drives the loop.
This paper is concerned with whether the loop closes, not what happens after. But it would be unfair to outline the path without showing the cliff beside it. Though we'll jump off this cliff in the next work.
Conclusion
Most thinking about recursive self-improvement starts with capability. This one starts with creativity. While I do not argue that it is the only thing you need to attain the loop, it is a critical angle that needs more consideration.
This lens reveals two threads worth pursuing: the combinatorial recursive loop, and parallel loops.
Regardless, the picture is clearer than it was, and the gap is smaller than most people think.
Therefore, what happens inside it is the most important work there is.